Your next expansion can stall long before construction starts, because the local grid can’t deliver power when you need it. For data centers and other energy-intensive operations, power availability is now a core business constraint.
That shift changes how you plan new sites, upgrades, and electrification projects. EcoStruxure Resource Advisor Power Availability is built to surface those risks early, so growth decisions rely less on assumptions and more on evidence.
Why power availability has moved to the center of growth planning
For years, site planning often started with land, labor, access, and cost. Power was still important, but many teams treated it as a later-stage utility coordination task. That order no longer works in many markets.
Electricity demand is rising across data centers, industrial operations, and new electrified loads. At the same time, utility headroom is limited in some regions, and grid upgrades can take years. Industry coverage now reflects that shift, with both Power Is the New Constraint in Data Centers and Power Availability Analysis: The New Priority in Data Center Site Selection framing power as a first-order siting issue.

If a project needs large new load, the question is no longer only “Can we afford to build here?” It is also “Can this grid support the load, on the timeline we need, with a risk level we can accept?” That is a much harder question, and it reaches well beyond a single utility conversation.
Growth plans fail on schedule long before they fail on strategy when power is unavailable.
This matters for existing facilities too. A company may have a good site, a strong market, and capital ready to deploy. Yet if the local grid cannot support expansion, growth slows anyway. In practice, that makes energy intelligence part of corporate planning, not only a facilities issue.
What EcoStruxure Resource Advisor Power Availability is built to do
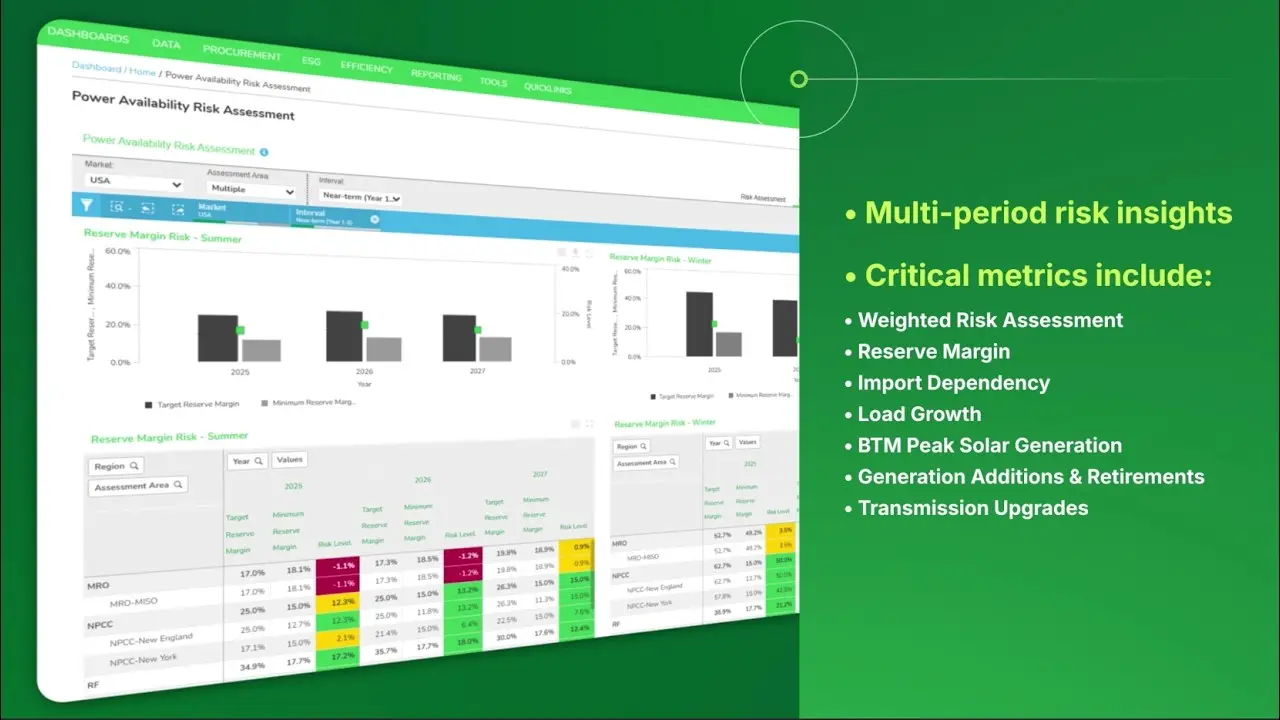
EcoStruxure Resource Advisor Power Availability is a forward-looking digital tool focused on one job, helping organizations assess and manage power availability risk across geographies. According to the product description, it provides up to a 10-year outlook across a range of critical metrics.
That long view matters because grid constraints do not appear overnight, and they rarely clear up quickly. A tool that looks ahead can help teams spot where capacity risk is manageable, where it is rising, and where it may affect schedule, cost, or project viability.
The tool is built on more than 20 years of energy market intelligence. That is an important point because power availability planning depends on credible market context, not only a snapshot of current conditions. Teams need enough depth to compare regions, test assumptions, and build risk assessments that leadership can trust.
It is also aimed at operations where power is a hard requirement, not a nice-to-have. The video and description both point to data centers and other energy-intensive or energy-critical operations. In those settings, power delays can mean delayed revenue, stranded capital, or both.
For readers who want broader context on Schneider’s Resource Advisor family, this overview of the Schneider Resource Advisor Plus platform shows how Resource Advisor fits into larger energy and sustainability workflows.
The planning questions it helps answer
A useful way to understand the tool is to look at the kinds of planning questions it supports.
| Planning need | What the tool helps assess |
|---|---|
| New site selection | Which geographies appear better positioned for new load |
| Expansion at an existing site | Where current sites may face power availability risk |
| Long-range planning | How conditions may change over a period of up to 10 years |
| Schedule protection | Where off-grid energy or efficiency measures may be needed |
| Decision support | Data-driven insight for credible risk assessment |
The core value is simple. It reduces guesswork in decisions that carry high capital and schedule exposure.
How the tool improves site selection decisions
Site selection often involves a long list of filters. Teams may compare land cost, tax structure, logistics, workforce access, fiber, and water. Those factors still matter, but power now needs to move much earlier in the screening process.
EcoStruxure Resource Advisor Power Availability is designed to help identify where the grid can support growth and where it may not. That changes the quality of the shortlist. Instead of spending months evaluating sites that later fail on electric service timing, teams can screen for power risk earlier.
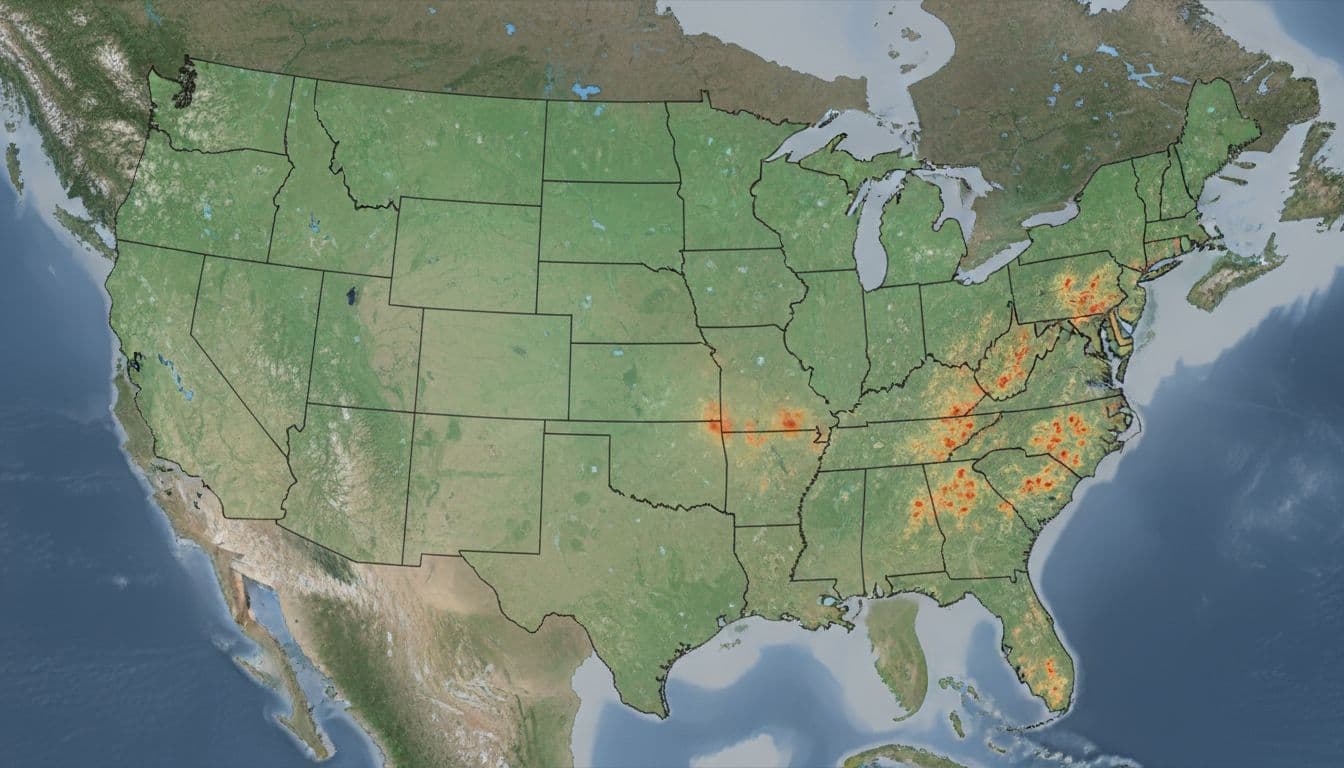
This geographic view is especially useful when comparing regions. A company deciding where to place future load does not need only a map of utility territories. It needs a way to judge which areas offer a stronger path to timely service. That is why market commentary has started to emphasize a grid-first approach to site selection.
The same logic applies to current facilities. A site that works well today may not have enough headroom for the next phase of growth. With better visibility into power availability risk, planners can avoid treating an expansion as a sure thing when the grid may not support it on the needed timeline.
This also helps internal alignment. Real estate, operations, finance, and executive teams often view site risk through different lenses. A forward-looking power assessment gives them a common frame. That can speed decisions because the discussion shifts from opinion to documented risk.
Why energy-intensive and energy-critical operations need this kind of visibility
Not every facility faces the same power risk. A light commercial site may have more flexibility than a hyperscale data center, a semiconductor plant, or a large industrial expansion. The harder the uptime and load requirements, the less margin there is for surprise.
That is why the tool is positioned for energy-intensive and energy-critical operations. In these environments, power is part of the production system itself. If new capacity is delayed, the whole project can slip.
For data centers, the risk is obvious. Compute demand may be ready, customers may be ready, and the building may even be ready. Yet without enough grid support, the site cannot deliver the load it was built for. For industrial operations, the issue can be similar. Electrified processes, large motors, or expansion phases may depend on service levels that the local grid cannot supply in time.
This is where planning and operations start to connect. Early siting analysis reduces risk before construction, while operational monitoring helps teams use the power they have more effectively after a site is live. For that second layer, a platform such as this EcoStruxure Power Operation overview shows how real-time monitoring and control fit into modern power management.
What happens when the grid cannot support the load
A constrained grid does not always mean a project stops. It means the plan needs another path.
The product description makes that clear. It highlights where the grid can support growth and where companies may need off-grid energy or efficiency measures to stay on schedule. That is a practical planning outcome, because it frames constraints as something to manage, not something to discover too late.
In broad terms, organizations may need to consider a few responses:
- On-site or off-grid energy options to support part of the required load
- Efficiency measures that lower the amount of new capacity needed
- Adjusted expansion timing to match available power
Each of those choices has cost, timing, and design implications. Therefore, the earlier the risk appears, the better. A late surprise usually forces expensive workarounds. An early warning gives teams time to compare options in a structured way.
Efficiency is especially important because lowering required load can change the whole feasibility picture. Better measurement and visibility help there. Teams that want to improve site-level insight can see how to visualize energy data on EcoStruxure PAS800 as part of a stronger energy data foundation.
The best time to address a power shortfall is before the project schedule depends on power that may not arrive.
Why a 10-year outlook changes the quality of the decision
A point-in-time answer is useful, but large projects do not live at a point in time. They move through site selection, utility coordination, design, procurement, construction, commissioning, and later expansion. That is why a multi-year view has more value than a simple current-state check.
EcoStruxure Resource Advisor Power Availability offers up to a 10-year outlook across critical metrics. Even without listing every metric publicly in the video, that framing tells you what the tool is for. It is built to support planning over the same horizon that capital programs and infrastructure investments often follow.
That helps in two ways. First, it supports stronger site comparisons, because teams can look beyond today’s apparent headroom. Second, it supports more credible risk assessments for leadership. If the business is committing to a location, it needs confidence that the power story is not based on a narrow snapshot.
A long-range view also reduces false certainty. A site may look fine under current conditions, yet still face medium-term constraints as regional demand grows. On the other hand, another location may offer a better growth path even if it is less obvious on first review. The point is not to predict the future perfectly. It is to make long-range decisions with better evidence.
Turning power risk into a planning advantage
The strongest message behind this tool is that power risk should be handled upstream, before it becomes a project delay. That is the shift many organizations are now making.
Instead of treating energy availability as a downstream utility issue, planners can bring it into site selection, capital screening, and expansion strategy from the start. That makes decisions faster because weaker options are filtered out earlier. It also makes decisions stronger because the remaining options have already been tested against a critical constraint.
For organizations managing broader energy performance across sites, this view also fits within larger Schneider Electric energy management solutions. Power availability is one part of the picture, but it is a part that now shapes where and how growth can happen.
Power planning now starts with grid reality
The old assumption that power will show up when a project is ready no longer holds in many markets. For data centers and other high-load operations, growth planning now starts with a harder check, whether the grid can support the load, in the right place, on the right timeline.
EcoStruxure Resource Advisor Power Availability is built for that exact problem. Its value is not only in mapping risk, but in helping companies make better-timed decisions about where to grow, where to wait, and where alternative energy or efficiency strategies may be needed.
When power becomes the gating factor, better visibility is not optional. It is part of basic project discipline.